V3的说明
介绍
如果读者看到这一段文字,说明您看的是本书3.0以上的版本。
我决定要升级这个版本的主要原因是这几年大语言模型(LLM)有了很大的发展,为我们解释《道德经》提供了更多的概念工具,让我们可以更容易沟通《道德经》里面描述的概念。我希望引入这些概念工具来帮助读者更好理解《道德经》想要表达的东西。
我不希望上面这个表述让不是LLM领域的读者感到焦虑,觉得这个版本会让你看不懂。实际上我没有打算改变本书的整体描述内容。你可以认为这个版本我只是增加了给不是做LLM的读者一些科普,让你可以更好理解大语言模型是怎么工作的。在你理解这些细节后,你就会形成新的概念,我们就可以用这些概念更好地认识《道德经》所表达的内容了。
这个道理就好比你没有见过狗,也没有见过猫,我给你形容狗,这会很困难。但如果我搞到一只猫给你看看,之后我再用猫去类比狗,这个沟通就容易多了。
这里的“猫”,就是我们在沟通“狗”的时候用的“概念工具”。
所以,我们也不是像某些喜欢附会的人那样,说什么“老子在两千多年前就已经参透LLM了”。LLM的概念可以用于理解《道德经》,是因为它们研究的是同一个领域:语言的特征。但老子研究语言的特征是为了解决高层决策的问题,而LLM研究语言的特征是为了解决知识的抽象问题。
认识LLM
我们很多人对LLM的具象认识就是使用ChatGPT、DeepSeek、豆包等这些工具的认知:聊天机器人。这个东西很像一个人,你问它问题,它回答你问题。
过去计算机模拟的聊天机器人大部分都是基于“逻辑思维”的。什么意思呢?就是你输入一句话,计算机必须通过一组逻辑判断,根据这些逻辑判断固定返回特定的回答。
这种判断模型经常是这样的:
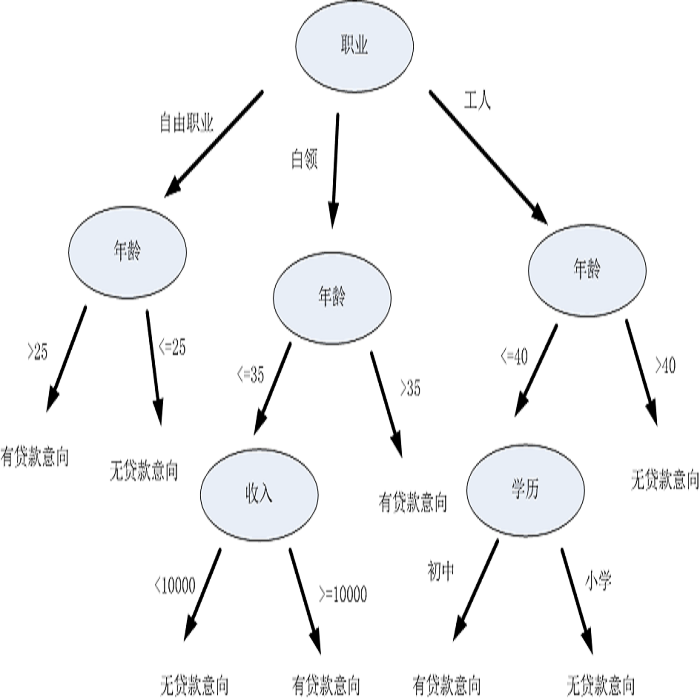
无论你问什么,它都必须进行“逻辑分类”,然后根据不同的分类走入不同的逻辑子类,然后决定某种固定的反应。很明显这种“智能”非常死板,它更像人的“记录”,而不是人的“智能”。人的语言行为非常复杂,有大量的情绪、隐喻和随意性在其中。这些东西用这种生硬的模型是模拟不了的。
而现在的LLM可以表现得非常拟人。比如下面是我和用ollama运行的一个glm-5.1:cloud模型对话记录(其中“>>>”开头的行是我的提问,后面是LLM的回答)::
>>> 《道德经》是讲什么的?请简单总结一下。
Thinking...
1. **理解用户的请求:**
* **主题:**《道德经》。
* **问题:**它是讲什么的?请简单总结一下。
* **目标:**用中文提供一个清晰、简明、易懂的总结,抓住这本经典的核心精髓,而不至于陷入过多的学术细节中。
2. **解构《道德经》:**
* *作者:*老子。
……(注:这些Thinking都很长,我们只是表明有这个部分,具体内容我们就省略了,下同)
...done thinking.
《道德经》是春秋时期老子所著的哲学经典,全文仅五千余字,却是中国传统文化的重要基石。
简单来说,它讲的是**“宇宙的客观规律”**与**“人类的生存智慧”**。
可以归纳为以下五个核心要点:
**1. 道:宇宙的本源与规律**
“道”是《道德经》的核心概念。老子认为,“道”是天地万物产生的根源,也是万物运行的内在法则。它看不见、摸不着,却无处不在。核心主张是**“道法自然”**,即万事万
物都要顺应自然规律,不要违背天性。
**2. 德:顺应“道”的智慧与品行**
“德”不是指世俗的道德说教,而是指“顺应道”的行事方式。当一个人或事物顺应了“道”的规律去发展,表现出来的品质就是“德”。最高级的“德”是默默奉献、不求回报(
“上德不德,是以有德”)。
**3. 无为:不妄为,不强求**
“无为”是《道德经》最常被误解的概念。它**绝不是什么都不做**,而是“不妄为”“不强求”——不违背规律去瞎折腾,不凭主观意志去强加干预。顺势而为,反而能把事情做
成(“无为而无不为”)。
**4. 辩证法:物极必反,柔能克刚**
老子看到了世界的对立与转化。美丑、难易、长短、高下都是相依相存的;更重要的是,事物发展到极点就会向反方向转化(“反者道之动”)。因此,老子极力推崇“柔弱”,认
为柔弱胜刚强(如牙齿坚硬易脱落,舌头柔软能长存),主张为人处世应“守柔”“知足”“不争”。
**5. 修身治国:从个人到天下的通则**
《道德经》把个人修养与治理国家看作是同一套逻辑:
* **对个人**:主张清心寡欲,收敛锋芒(“和光同尘”),知足常乐。
* **对治国**:主张统治者少干预、少收税、少发动战争(“治大国若烹小鲜”),让百姓自然生息,最终达到“小国寡民”的理想平和状态。
---
**💡 一句话总结:**
《道德经》告诉我们:**认清宇宙规律(道),顺应自然(德),放下执念(无为),以柔克刚(守柔),最终达到内心安宁与外界的和谐。**
>>> 那为什么 “道可道,非常道,名可名,非常名”呢?这里道和名的关系是什么?
Thinking...
1. **分析用户的请求:**
* **问题1:**为什么说“道可道,非常道;名可名,非常名”?
* **问题2:**这里的“道”与“名”是什么关系?
* **目标:**对《道德经》中最为著名的开篇第一句提供一个清晰、直观且逻辑严密的解释,特别侧重于“道”和“名”的动态关系。
2. **解构“道可道,非常道”:**
* *第一个“道”:*名词,终极真理,宇宙的本源。
* *第二个“道”:*动词,言说、表达、定义。
* *常道:*永恒的、恒常的、绝对的道。
* *含义:*如果“道”是可以被人类语言说出来的,那么它就不是永恒的、绝对的道。语言限制了“道”。
……
...done thinking.
这十二个字是《道德经》开篇第一句,也是全书的“总纲”和最大难点。理解了这句话,就拿到了进入老子哲学世界的钥匙。
我们可以分两步来拆解:先解释字面意思,再理清“道”与“名”的关系。
### 一、 字面意思拆解
在这句话里,“道”和“名”都出现了两次,但词性不同:
* **道可道,非常道**:
* 第一个“道”:名词,指宇宙的本源和终极规律。
* 第二个“道”:动词,指言说、表达。
* 第三个“道”:名词,永恒的道(常道)。
* **翻译**:可以说得出来的“道”,就不是永恒的、绝对的“道”。
* **名可名,非常名**:
* 第一个“名”:名词,指名字、概念、标签。
* 第二个“名”:动词,指命名、定义。
* 第三个“名”:名词,永恒的、绝对的名字/概念(常名)。
* **翻译**:可以被定义出来的“名”,就不是永恒的、绝对的“名”。
**连起来的意思就是:**
真正的宇宙终极规律(道),是无法用语言完全表达出来的;一旦你用语言去定义它、给它贴上标签(名),它就变成了有限的概念,不再是那个无限的、永恒的真相了。
---
### 二、 “道”与“名”的关系是什么?
“道”是客观存在的本体,“名”是人类主观赋予的认知工具。它们的关系,可以归纳为以下三点:
#### 1. 目标与地图的关系:名指向道,但名不是道
“道”是那个真实存在的、浩瀚的宇宙真理;“名”是我们为了理解和交流而创造的语言、概念、逻辑。
就像**“手指”和“月亮”**。语言(名)是手指,真理(道)是月亮。手指可以指引你去看月亮,但手指绝不是月亮。如果你死死盯着手指,就永远看不到真正的月亮。
#### 2. 无限与有限的关系:名是对道的“降维切割”
“道”是完整的、无限的、浑然一体的。而人类一旦要“命名”,就必须进行区分(这是善、那是恶;这是大、那是小)。
一旦有了区分,就把无限的道“切割”成了有限的概念(名)。
所以老子说“非常名”——任何概念标签,都只能描述事物的某一个切面,而不能代表事物的全貌。**就像你可以说水是“液体”,但“液体”这个词根本无法涵盖水的全部特性。
**
#### 3. 束缚与超越的关系:执于名,则失于道
这是老子最深刻的洞见:**语言概念既是认识的工具,也是认知的牢笼。**
当我们习惯了用“名”(好坏、美丑、高低、贫富)去看待世界时,我们就产生了执念和偏见,从而偏离了那个自然浑朴的“道”。
比如,定义了“美”,就随之产生了“丑”;有了分别心,就有了争抢和痛苦。所以要真正体悟“道”,必须“忘名”——放下僵化的概念和标签。
---
### 三、 为什么老子开篇就讲这个?
老子在第一章抛出这句话,其实是在给读者打一剂**“预防针”**:
他是在告诉你:**我接下来写的这五千言,也只是“名”(语言的标签),而不是真正的“道”。** 如果你死记硬背这些文字,你就错了;你必须透过文字(名),去感受文字背后
那个不可言说的真实规律(道)。
**总结一下:**
“道可道,非常道”揭示了真理的不可言说性;
“名可名,非常名”揭示了概念的局限性。
**“道”是实质,“名”是外衣。** 老子是在提醒我们:不要把外衣当成了实质,不要把地图当成了疆域,要超越语言和概念的束缚,去用心体悟那不可言说的自然规律。
这个回答,虽然我不完全同意它的说法,但比我在网上看过的大部分解释都已经要靠谱得多了。
但我不是强调这一点,我强调的是:它确实已经很像一个“人”了。它甚至还有一个思维的过程,先考虑你的意图,然后才正式回答你(这是一种称为“思维链”的技术,不是每个LLM都会提供,我们后面会更详细一点去讨论它。)这是靠前面那种粗糙的决策树不可能做到的。
这样的对话能力过去对计算机是个巨大的挑战,因为传统的计算机基本上是用来做逻辑或者说“数值”运算的。你让它计算3+3等于几,或者如果3+3大于5就输出6,否则输出1……这些东西传递给计算机都很容易做到,但你要让它谈谈对3+3=6的感想,并据此写一篇三百字的议论文,这它就没法弄了。也许你可以内置一个回答给它,让它固定回答这个,但只要你针对它的回答再问一句,这个组合逻辑它没法都内置,它就会回答得牛头不对马嘴。
这里的关键在于,计算机的逻辑都是人教给它的,除了复合逻辑,人都没法教它其他东西,而我们人自己不是这样学习知识的。
维特根斯坦在他的《逻辑哲学论》(我看的英文版本叫Tractatus Logico-Philosophicus》中用了6章来描述他的逻辑概念定义和表示法,而最后一章,只有一句话(中文是我翻译的)::
What we cannot speak about we must pass over in silence.
我们不能说的,必须在沉默中传递。
我看的版本的英文翻译者(D. F. Pears和B. F. McGuinness)在前言中把这句话补全了::
what can be said at all can be said clearly, and what we cannot talk about
we must pass over in silence.
能被说的可以被说清楚,而不能被说的,我们必须在沉默中传递。
也就是说,通过逻辑,能说清楚的我们都能说清楚,我们不能说清楚的,只能意会。
请注意,这是逻辑,不是“沉默是金”这种心灵鸡汤。
“苹果是红的,这个水果不红,所以它不是苹果。”这句话可以说清楚,这是逻辑的。但什么是苹果?什么算水果?苹果是一种水果吗?……这没有说清楚,我们的“清楚”,是在逻辑空间中清楚的,但某个物体我们认为是苹果,这个东西是“你知我知”,这个东西是在沉默中传递的,它不是我们逻辑空间中的一部分。
你当然可以进一步解释什么是苹果,什么是水果。但你永远需要其他概念去解释它,这些概念具体是什么,就必须在沉默中传递。
传统计算机擅长解决的是逻辑空间中的问题,逻辑永远都可以得出结论,最多只是计算快慢的问题,但它不能解决“在沉默中传递”的问题。这是因为,我们人就只能把自己思想的“逻辑”部分传递给它,我们没有能力传递我们自己都说不清楚的那些“你知我知”的东西给它。就算它产生一些随机的信息出来给你,你也不觉得它有“智能”,因为你和它不能“你知我知”,没法共情。
具体一点来说,计算机要求你先定义了a=3, b=4,它可以给你推理a*b=12,但为什么a=3,b=4,这是你要预先定义的。这就是维特根斯坦理论中的“逻辑”的部分,逻辑要求你先定义了属性,然后在这个概念空间里面推理,这个推理过程就是清晰无误的,但预先定义之前的部分,都是“不可言说”的。
理解这一点,我们就容易明白《道德经》说“道”不可“道”的含义了。“道”包含无数细节,我们感知到它的是它影响的我们对这个世界的认识(“名”),我们谈的也是我们这个“名”,但这个“名”并非“道”本身。所以《道德经》说的“天地”,并不是真实的,它是我们对“道”的认识,是“名”。《逻辑哲学论》说的“World(世界)”也一样,它是我们对Thing(“东西”)的认知,不是Thing本身。
“道”可以用名去“道”,但“名”只是“道”的一个我们自身的一个“关注点”(妙),不是“道”的本体,也不是它的全部信息。名是道和我们本身的感官共同作用的结果,它包含了我们自己的成份在里面。所以名里面包含了“众甫”(使用这个名的人)的本身的信息,我们看名不但看到了“道”的部分特征,我们也看到了“众甫”的部分特征。商人描述的黄金和矿工描述的黄金包含着不同的信息。
我们这里介绍LLM,就是用一个更加直观的方法,让大家感受到这个在沉默中传递的东西具体是什么样的。看看我们觉得没法“数字化传递”的那些恍恍惚惚的“你知我知”的概念,是怎么通过明确的数字传递过去,让冷冰冰的机器,也能和你“共情”的。
大语言模型的数学原理
线性回归
本章我们用线性回归来解释一下机器学习最基本的原理。
如果你不记得线性回归具体怎么做的,不要紧,你大致知道它是什么东西就行了,相关的知识我们后面会一点点给你提回来。但如果你说你完全不知道“线性回归”是什么,那这个V3的升级的内容不适合你。不过,这不影响你继续看这本书,少数地方提到LLM有关的比喻,你略过就是了。我会明确分隔这部分内容的,没有数学基础的可以把这些内容整体忽略掉。
还有些读者可能有非常丰富的机器学习知识,这种情况我建议你可以加快阅读速度,但我不建议你跳过这些介绍,因为你的抽象方法不一定和我的一样。
最简单的线性回归方法是尝试得到这条方程的两个参数(a和b):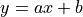 。
。
假定你有两个指标x和y,比如给水缸放水的分钟数和水缸的高度,或者说开车的时间和开车的距离之类的,你进行很多次的测量,知道很多个(x, y)的值,现在你想知道a和b,以便以后你知道x就可以预测到y,这个通过很多的(x, y)的经验数据得到a和b的方法,就叫“线性回归”。
当然,如果是纯数学,凭初中的数学知识,我们知道只要两对(x, y),我们就可以得到两条二元一次方程,就足够解出a和b的值了。但工程上,我们每个测量结果都是有误差的,所以实际上我们是有很多的(x, y),然后我们尝试获得“最好”的a和b,让所有的(x, y)的综合误差是最小的。这个算法就比解方程复杂一点了。
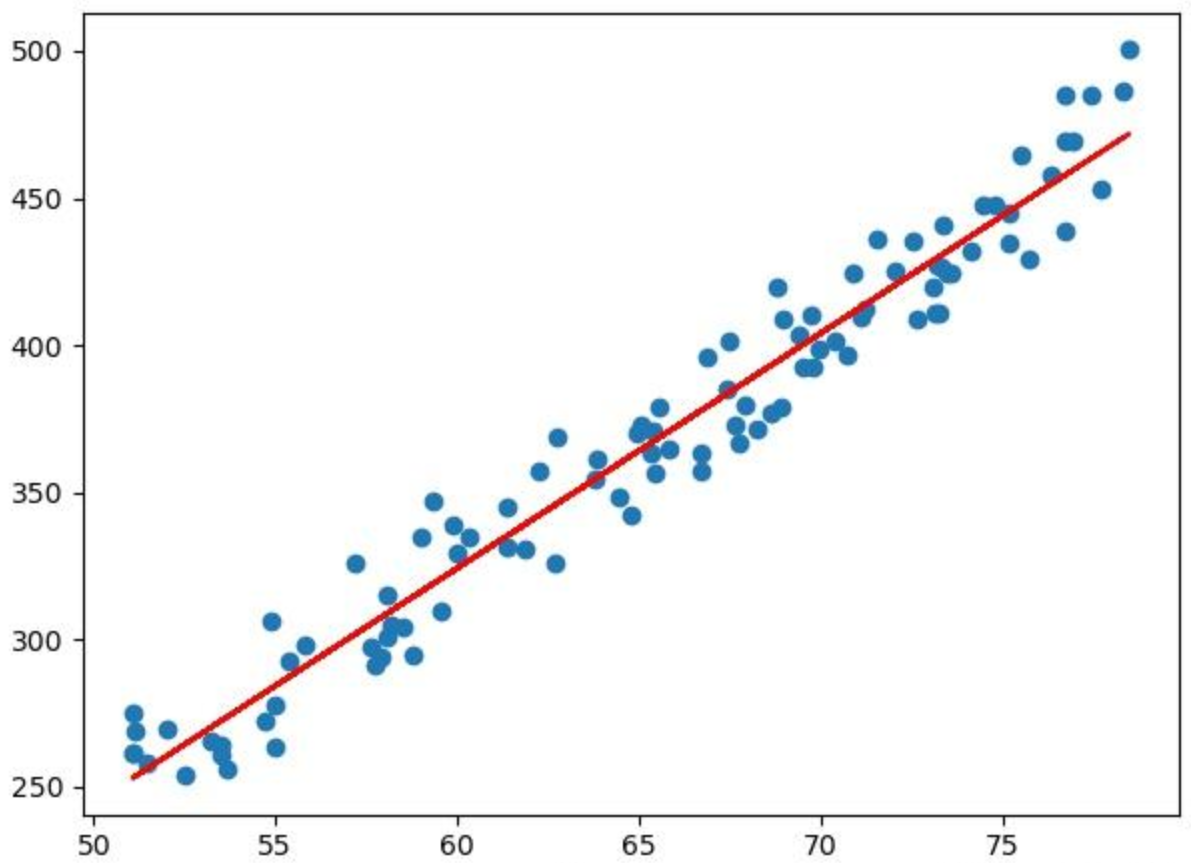
一般我们会先人为定义一个误差函数(称为loss,比如均方差就是一种常用的loss函数),用来评估我们不同的a和b,造成多大的误差。然后我们把所有的(x, y)(注意,我们这样说的时候,(x, y)是向量,包括所有的点)输到loss中,我们求a和b等于多少的时候,loss能达到最小值。
这有很多数学方法,但在机器学习中用得最多的是“梯度下降法”。基本原理是先给a,b设定一个随机的值,然后在(a, b)的位置上,对loss函数求偏导(注意,对于loss函数,(a,b)是变量,而(x, y)是常数了),然后把a, b各自向着偏导的负方向移动一个小Delta(称为Learning Rate),如此反复多次,loss就可能向着最小值慢慢下降了。
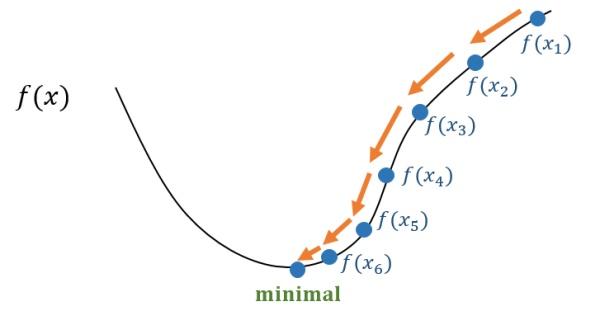
这个具体要多少次常常是试出来的,调整Delta不断比较loss是不是可以接受,通常慢慢就能找到越来越好的a,b的值了。这里有很多细节的工程问题需要解决,比如这个Learning Rate设置多大才能平衡效率和过度调节的问题。但原理就是这么个原理了。
线性回归是最简单的机器学习方法了,我们可以通过它来对比人脑的学习过程:我们把(x,y)称为“训练集”,这是我们的“经验”,它相当于我们认识世界的时候不断看到的世界的规律。而(a, b)就相当于我们的大脑,我们在小孩的时候,a, b可能是些随机的值,但我们看见了,听到了,摸着了,得到了很多的经验,这些经验改变了我们的a和b,我们就记住了一些东西了,这个a和b,我们称为“参数”,“模型”,或者“模型参数”。然后我们再遇到一个新的x,我们就能进行“预判”,对y是多少就有了一个预期了。如果我们把这个过程看作一个黑盒方程,学习就是一个这样的东西:

我们感受到外界的信息,根据这个信息和内部参数综合做出决策,然后这个决策会给我们反馈,这个反馈和输入共同构成(x, y),改变我们的内部参数,然后影响我们的下一个决策,我们就在这个过程中,反复改进我们脑子中的模型参数,这些参数,和输入输出不是直接相关的,但输入输出又和它们有千丝万缕的关系。
神经网络
简单的线性回归只有两个参数,通用的线性回归算法x是个向量,线性方程变成:
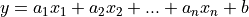
这可以容纳更多的参数,但数量也非常有限,这几个参数形容不了世界的复杂性。世界的规律不是线性的,甚至不是多项式可以表达的。
数学家发现了一种可以容纳更多参数的,可以适配各种各样的“规律”,这就是“神经网络”。神经网络这个名字听着很神秘,其实作为方程,它是很简单的,如果用大白话来形容,你可以把它称为“权重加成”。
在介绍这个方程前,让我们再回顾一下线性回归的原理:你学习的可能是“放水时间”和“水池高度”这两者的规律,但你学习以后,你记住的是“斜率”和“截距”这两个概念。这是不是很奇怪?放水时间和斜率,似乎是风马牛不相及的,但它们之间居然存在规律!
记住这个特征,人脑记住规律就是这么做的。
大部分时候,我们考虑问题,其实就是把很多的规律(参数),这个多少份,那个多少份,糅合到我们的参数中。比如说,一个游戏角色好不好,我们拿他30%的武力值,40%的智力值,25%的敏捷和5%的防御,权重一加,我们就去和其他角色比高低了。
这个[武力,智力,敏捷,防御]的向量,乘以[0.3, 0.4, 0.25, 0.05]的向量(这种乘法称为“内积”),就是一个权重加成,可以得到这个角色另一个角度的考评,这种考评结果也是一种向量比如[招聘费用,战场生存力]。神经网络就是一个这样的计算过程:

所以,尽管说得神秘兮兮的,这个神经网络的算法其实非常简单。就是把每个输入都做一个权重加成,然后全部加起来,得到另一个维度的不同参数而已。它被称为神经网络,因为它的样子很像人的大脑神经组成结构:这个方程的输入就是一个个神经元的触觉,触觉感知到前面的刺激,就把这种刺激传递给下一个神经元,这个连接前后神经元的组织是可以被“训练”的,所以这里这些[40%, 30%, 25%, 5%]遇到反馈后,就会发生改变,产生“学习”。下一级把这些刺激收集起来,可以传递给下一级。这样会产生一个多级的传递和学习结构:

这种结构伸缩性很强,你可以在每层上任意增加更多的神经元,它的内部权重的参数就增加了,你也可以增加更多的层,这样整体也会产生更多的参数。
有一个这样的算法,我们就得到一条比线性回归(包括任意曲线回归)更大,更自由的方程。这个方程,就称为“神经网络”。很多刚接触神经网络的人都把这个东西理解成现实世界互联网网络那种“传递信息”的东西(比如光纤,wifi等)。实际上这两者不是一个意义上的网络。“神经网络”形容的是这条方程的组成形式。它本质是一个方程,不是一种传递信息的介质。
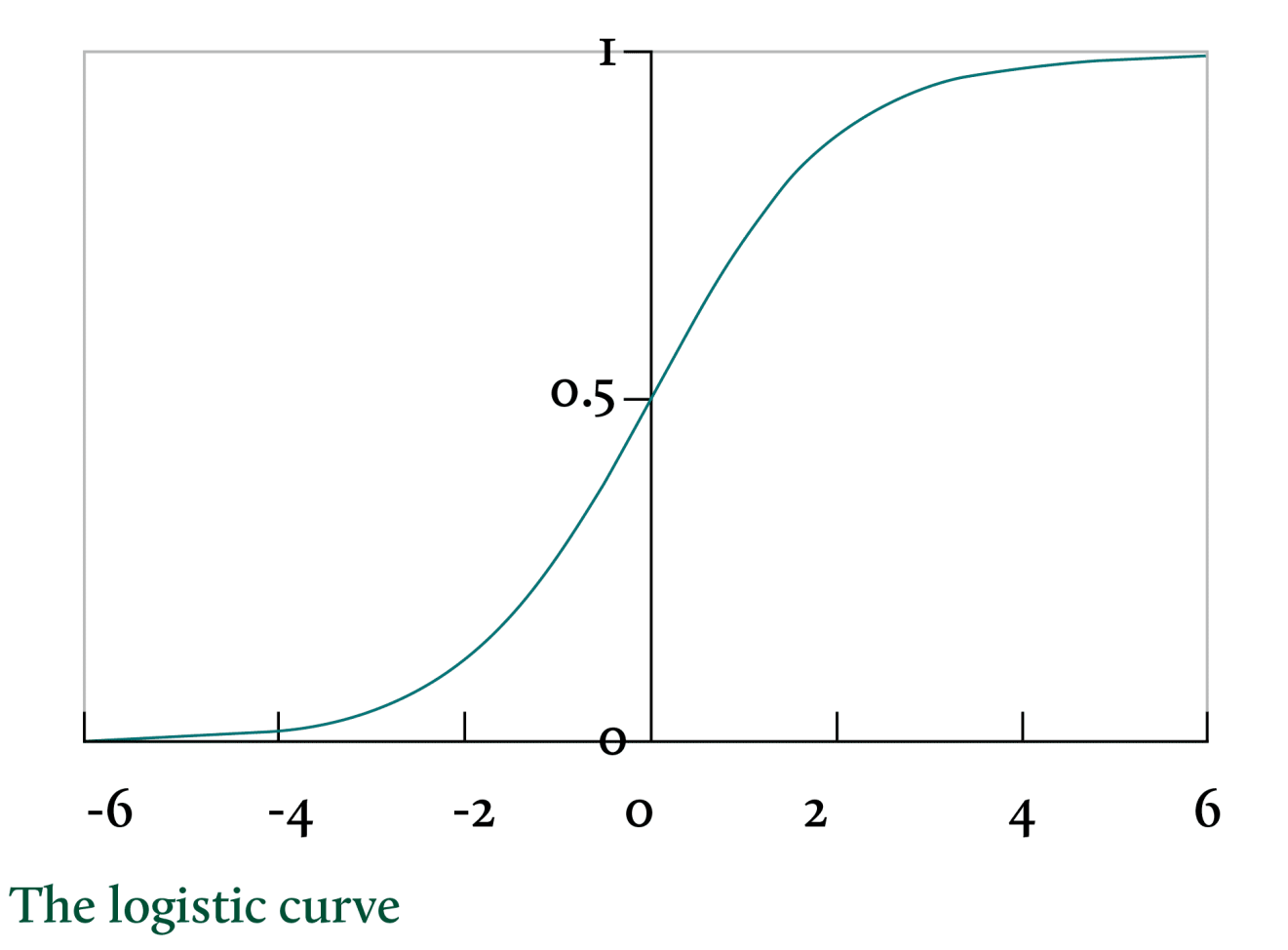
当然,前面我们只是介绍原理,在实践中,我们其实除了权重还会加上线性回归一样的“截距”偏置,以便在某个权重上产生本身的“权重”(和任何输入无关)。我们还会通过把结果叠加一个“激活函数”去对结果进行过滤。这个目的其实主要是“非线性化”。前面我们说过了,线性回归做梯度下降的前提是方程可导,但权重计算基本上形成的是一条折线,这会让结果常常是不可导的,所以,加一个要素进去,让这个结果不要对输入反应得那么“生硬”,这些激活函数通常不会对输出造成很大的改变,就是简单让它“柔和”一点而已,比如下面这个Sigmoid函数就是一种常用的激活函数:
所以,作为忽略工程实现的原理理解,我们基本上理解权重的部分就够了。
神经网络常常被比喻成人脑的神经网络,其实不利于有数学思维的人理解的。让我给你换成线性代数的概念你就好理解了。
前面我们用游戏角色的例子展示了神经网络是怎么把武力-智力-敏捷-防御这个四维向量转换为一个招聘费用-战场生存力的二维向量的。线性代数没有忘光的读者应该很敏感地发现了,这其实是一个“线性变换”。线性变换就是坐标系只做加权或者旋转变化的变换:

线性变换能维持原始坐标系的很多特征,比如平行线会保持平行,所有面积都保持等比例缩放,等等。如果不考虑严格的数学定义,你可以认为线性变换是一种“变换后你还能大致认出原来的图形是什么样子的”的变换。
使用线性变换,原坐标系的任何一个坐标,都可以用相同的变换算法转换为新坐标系的点。而这个算法就是前面说到的“权重加成”。最后就可以表达为一个矩阵乘法。
比如你有一个4维的变量[x1, x2, x3, x4],乘上一个4x2的变换矩阵,你就可以得到一个2维的变量[y1, y2],计算方法就是:
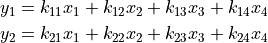
对应的变换矩阵就是:
![\left[ {\begin{matrix} k_{11} & k_{12} & k_{13} & k_{14} \\ k_{21} & k_{22} & k_{23} & k_{24} \\\end{matrix}} \right]](_images/math/d4d129e56c019b0575791b3f32bb2422898fe434.png)
所以,从理解算法的角度我们不需要想那么复杂的神经网络结构。其实每个神经网络(层)计算,就是一个变维的过程:我们输入一个向量,乘以变换矩阵,得到变维后的向量。也就是同一个问题,在另一个维度上的认知。
扩展一下,如果我们把前一个坐标系的t个坐标合并起来组成一个矩阵,把这个矩阵乘以变换矩阵,我们会得到一个t个坐标组成的后一个坐标系的矩阵。换句话说,变换矩阵不但可以作用在一个点上,也可以作用在一组点上,把每个点都做一样的线性变换。我们很容易把前一个坐标的一个图形,变换为新坐标系的新图形。记住这个小特征,它对我们后面理解Transformer模型会有帮助(其实这对几乎所有具体的大模型都有帮助)。
这给了我们一个新的方法来理解我们道德经的“恍惚”的概念。比如你看到一只猫,我们把你的眼睛看作是一个传感器,它捕获了1000个点的颜色,这个包含1000个数据的向量,就是你的恍惚,你都看见了,但你的神经网络对它进行了变维,变成了2000维的空间的坐标。现在你告诉我,这个2000维的数据表示什么?要说出来的话,我也只能说这是“猫”的信息,但其实你非要说它是什么,看起来它就是一个2000维的一个向量。什么时候它是“猫”呢?只能是这个2000维的数据穿过整个神经网络,经过一次次的变维,最终变成“猫”这个Token(Token的概念我们后面介绍Transformer的时候回过头来讨论)的时候了,这时,它就是一个“名”。
当我们细细地打开我们大脑的思考过程来看这个问题,我们就能更清楚看明白“名”和“道”的差距有多大了。从恍惚开始,你就已经离开“道”了。你的信息被反复变维,从各个角度来寻找潜在的规律,最终形成了你的一组Token(名),这就是你的认识。
现在我们可以抽象性地理解神经网络了,它是一条包含大量参数的方程,这些参数用作输入的变换矩阵,让我们从不同的维度去变换我们原来的认识,并且在这种认识的高层抽象上进行再次认识,从不同的层次上发现规律,记录在这个层的权重参数中。
神经网络每层的变换矩阵(又叫“权重矩阵”)就是它的“大脑记忆”。外部的刺激被权重矩阵所“判断”,形成了我们的认识,“认识”的规律反过来修正了我们的权重矩阵,改变我们对未来的“认识”。我们被外界的刺激中包含的规律和权重参数改变我们的认识,认识反过来又改变我们的权重参数。所以,学(接受刺激)而不思(通过反复递归我们的Token优化我们的权重)则罔,思(只是不断优化已有的信息)而不学(接受新的外部刺激)则殆(不会继续进步)。
神经网络中,把方程输入输出的两层称为“显层”(因为这里的概念还能和我们的认识保持一致),把中间的其他层称为“隐层”(这里已经发生变维,每一维是什么意思,已经没有对应的语言(Token)和它们一一对应了)。有了这个概念,我们就很容易理解《道德经》中说的“名和恍惚”两个概念是什么了。名是我们明确形成的概念,是我们在输出层上看到的数据,而恍惚是隐层的权重,这个信息存在在我们的脑子中,但我们不知道它是什么,我们说不出来,因为说出来的就是我们输出的Token,但我们还有大量从不同维度理解这些信息的“隐层权重”,这些东西你说它“没有”呢,这不对,因为我们还是能感知到它,但你说它有呢,你确实也说不出来。
所以,老子说“道之为物,唯恍唯惚”,“惚兮恍兮其中有象。恍兮惚兮其中有物”。信息都在其中,但你说它是什么,你说不出来。
我觉得,老子能在那个对这些基础研究都没有的情况下,直接感知到“恍惚”这个概念的存在,感知能力实在是非常强了。当然,我个人更认为这不是老子一个人发现的,这应该是我们的祖先进行大量的概念归纳后的共同智慧,否则它不可能这么指向明确地保留到今天。
Transformer
综述
Transformer是一种面向大语言模型的神经网络,现在几乎所有的大语言模型都是基于这个结构的模型来实现对话的。像我们很熟悉的OpenAI,DeepSeek,千问这样的模型,都是基于这个神经网络的结构的。当然,都有不同的改变,但这不影响我们通过这个基本的模型去理解大语言模型是怎么对输入的文字进行变维,最终变成一种“智能”的。
Transformer这个概念来自一篇Google公司的论文,叫《Attention Is All You Need》,翻译成中文就是“你需要的只有注意力”。这是直译,你不要当作一般人的语义来理解,不要觉得这是让你集中精神。这句话的意思是:我们做了各种大语言模型的实践以后,发现整个算法核心其实就只有“注意力”(这个算法)。
其中Transformer这个单词直译是“转换器”,它也是著名的漫画和电影《变形金刚》的名字,表示那些可以“变身”成汽车的机器人。我花时间把这两个语义介绍给读者,其实也是想强调一下:两种不同的语言,几乎是没法用一一对应的方式来翻译的。古人说的牛马,和现代人说的牛马,就不一样。大语言模型的“转换器”,和可以“变身”的机器人也不是一个东西。中文的机器人和英文的Android或者Robot也不是一个意思。注意到这个特征,也许有利于你理解Transformer的工作原理。
我们这里不翻译,把这个算法叫Transformer,主要就是想用它被创建时的原始语义。你可以想象如果我们把这个东西叫“转换器”,你很难不把它和泛泛的转换器的概念联系起来。
很多人批评英文在每个领域都创建了很多新词,不利于交流。其实这是把某个领域研究精细以后的必然选择,因为你就是要在这个领域创建独一无二的概念,好和其他概念区分。所以我们做计算机的,也愿意在中文中插英文概念,因为这样我们就可以和我们日常用的那个概念区分开了。这个问题不是中文本身的问题,英文一样存在,如果你经常看论文或者看数学证明,里面大部分变量都用罗马字符或者拉丁字母表示。这也是为了换一种语言来表达一个“独一无二”的概念。
Transformer的算法主要是论文中下面这张图描述的:
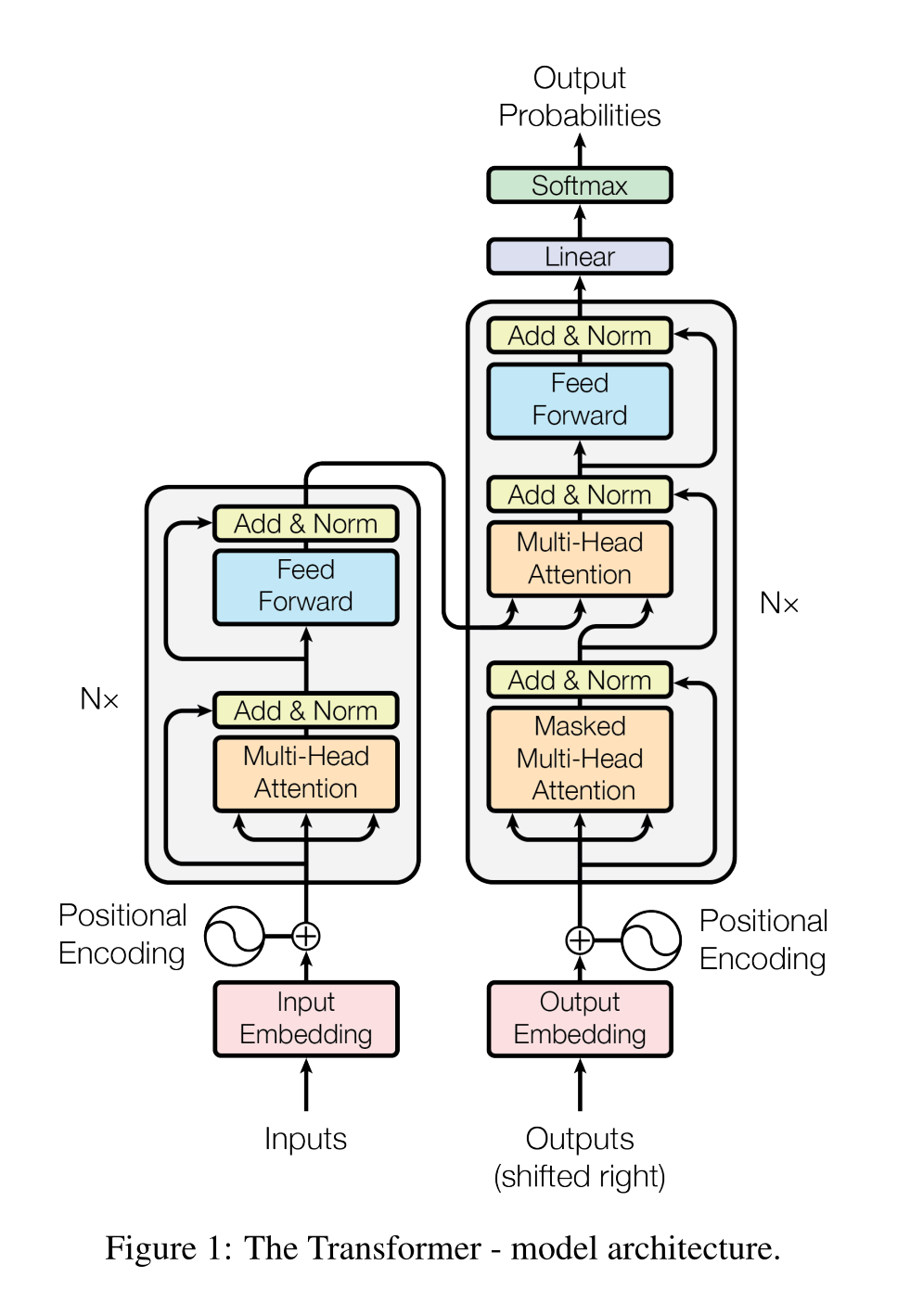
没有神经网络的基础,可能你不知道这个图是什么意思,但结合前面的介绍,我们现在应该比较容易给你解释它的原理了。
首先,这个图中的每个框,就是一个神经网络的层,里面带着自己的权重,可以训练,你输入的问题,变成一个矩阵,把这个矩阵输入到神经网络中,进行一次次的变维操作,根据变换矩阵(后面我们统一叫权重矩阵,前面的名字强调它对输入的改变作用,而权重矩阵强调的是它类似人脑的“记忆”功能),变成一个内部的“认知”(恍惚),这种恍惚的信息一层层传递,最后变成一个感知的输出,形成“概念”,变成说出来的对话,这就是Transformer的效果。
和人不一样,Transformer的认知过程和训练过程是互相独立的,你和Transformer对话,它和一层层的权重矩阵进行计算,最后输出对话,这个过程中权重矩阵是不改变的。
而训练是一个独立的过程,你给它输入大量的文档,小说,程序,对话,论坛的帖子等等,Transformer用前面说的话和后面的话进行“规律匹配”,通过梯度下降算法训练权重,让权重和这个规律实现“最小loss”,这个原理和线性回归是一样的。但人肯定是不用成本这么高的算法来训练自己的脑神经,具体它是什么方法,我也不知道。反正肯定不是这个方法(当然,人脑也记不住现在大语言模型记住的那么多信息)。但无论如何吧,Transformer在使用的过程中,它的脑子就不再“成长”了,这一点和我们人是不一样的。虽然你也确实可以把你后来和它的对话也放到它的训练数据中,但这两个过程是互相独立的。
我强调这个,主要是想告诉你,现在的神经网络,还和人是不一样的,你不能完全把两者对等,但研究神经网络,确实有助于我们类比我们很难用语言来表达的人脑的思维机制。
我们接着说这个结构的总体原理:这个图分成左右两个部分,你可以看到它有两个输入一个输出。为什么会有两个输入呢?我们看看它的用法你就知道了。我们设想一个对话::
你:你好
AI:你好,有什么可以帮你?
这个对话中,输入就是“你好”,输出是什么呢?——嗯,不是后面那句话,而是“你”。整个神经网络,只计算一个单词(称为Token),这个计算完成后,再次在右边的输入上输入“你”,得到“好”,然后把“你好”输入到右边的输入上,如此类推,得到::
,
有
什么
可以
帮
你
?
<EOD>
最后一个Token表示对话暂时结束。所以,你会发现,这整个计算过程,其实一直都是用前文推断后文。所以,整个AI对话,其实就是一个“补字游戏”,你不一定用它来对话,你完全可以写一些文字作为开头,然后让AI补全后面的文字。
所以,几乎所有的LLM模型都可以用来做文字补全,比如你给它“白日依山尽”,可能它会给你补成“黄河入海流”。由于你用这句文字“训练过”它,它的权重里面“记住”了这个“规律”,所以它大概率会这样回答你。
至于它为什么能被训练出“对话”的规律,那是因为这部分的训练数据是这样的::
<User>你好</User><AI>你好,有什么可以帮你?</AI>
所以,它也学会了对话类型的连串语句的特征。
从这里可以看到,就原来来说,“对话”和“补全”是同一个东西,我们介绍原理就介绍一个就行了,后面我们都用“补全”作为例子来讨论我们的问题。
Transformer这个“方程”,就是用一组神经网络层,充分暴露语言的特征,从而用权重记住这些特征。整个Transformer网络设计的重心,就是怎么把语言的规律充分暴露出来,让它在信息传递中尽量贴近人的思维特征,保留人思维会保留的特征,放弃人思维不保留的特征,从而让它“像个人”。
基础结构
Transformer模型分成左右两个部分,看起来非常接近。这个结构的基础来自过去的翻译软件。比如中译英。用过这种软件的读者应该知道,要做好整个句子乃至整个文章的翻译,你是不能一个单词,一个单词去直译的。因为两种不同的语言不是逐字一一对应的。强行一一对应翻译就会造成这种结果::
What's your name?
什么是你的名字?
这个显然很生硬,因为中文问人家名字是这样问的:“你的名字叫什么?”
这还算好了,复杂一点的遇到更多一些多义词,不联系上下文你根本不知道那个词应该译作什么。
所以,翻译软件会先把输入先翻译成一种“内部表达”(权重),然后再把这些内部表达,重新表达成另一种语言。这两个过程,就叫编码(Encoding)和译码(Decoding),前者把一种语言转换成内部表达,后者把内部表达转换成另一种语言。
这两者几乎是完全一样的,只是训练了不同的权重而已。Transformer继承了这个结构,所以它就有左右两个几乎一样的部分。你可以认为它就是一个翻译软件,把“问题”翻译成“回答”而已。
对于这个结构,我更想提醒读者的是:神经网络的设计,和一般设计普通的计算机算法很不一样。我们前面就说过,一般计算机算法设计的是“逻辑”。它是严格的,清晰的。设计多少层,每层应该是什么……这是有明确的“因果”关系来支撑决策的。但神经网络多一层少一层,有时根本不影响什么,因为训练过程会让这一层也向“实际的规律”靠近,这也没有精确的逻辑关系可以说。神经网络的算法设计,更重视的是如何“充分暴露重要的规律,隐藏多余的,没有意义的规律”。理解这一点,我们才能理解我们后面讨论的重点。
Token vs. Embedding
Transformer的输入是Token,就是“包含某种意思的词语”,让我区分一下:
当我们说“道德”的时候,和我们说“道”的时候,我们期望表达的含义是不同的。所以,就“意思”来说,“道德”和“道”,是两个Token。我们脑子里面思考“道德”的时候,是作为一个整体来思考它的,但我们有时又确实是把两者“关联”起来了。比如有些人想要拽文,说不定就会说出“道德,道德,必然要出乎道才能合于德”。如果道德和道是两个东西,我们不会说出这样的话。这说明在我们的脑子里,这两个Token是有关联的。但如果我们简单用一个数字来分别代表不同的Token,那么我们就会失去这种关联,而会创建另一种关联。
比如说,我们把所有的Token组织成一个列表,按顺序编码它,道排在11位,刀排在12位,而道德排在1234位。这个数据输入到神经网络中,神经网络就不会认为道和道德有关联,而会认为道和刀有关联,因为它们靠得很近。但我们人并不这样认为,所以,为了让神经网络更像人的思考模型,我们必须让网络忽略道和刀的相关性,而注意到“道”和“道德”的相关性。
所以,Transformer不用Token的字典下标来表示Token,它用整个字典所有Token的权重来表示单个Token。
这句话不好理解,看个例子就容易明白了。比如说我们的语言很简单,只有10个Token::
你 我 道 德 刀 道德 我们 飞机 月亮 的
0 1 2 3 4 5 6 7 8 9
为了表示“你”这个Token,我们先简单写成一个这样的向量::
[1, 0.1, 0, 0, 0, 0, 0.2, 0, 0, 0]
你可以看出来,这就是一个所有Token的权重矩阵。“你”这个Token,和字典中的“你”最接近,所以它在“你”对应的字典位置,权重就是最高的(例子中的1),它和“我”这个Token还有点关系,所以“我”的权重是0.1,而它和“道”没啥关系,所以权重就是0,……如此类推。
用这种方法表示Token以后,每个Token就只和其他Token有权重关系了,和字典顺序就没有关系了。这些权重经过一些实际文字的训练,每个Token就会有一组特定的权重了。
以前很多LLM都通不过一种测试:比如你问它Happy中有多少个p,它是回答不出来的,因为Token中并没有这个信息。但这个问题现在很多时候都没有了,这有很多办法解决的。一个最简单的方法是用一组文字训练LLM,直接告诉它happy包含哪些字符。之后它就能建立happy中有多少个p的知识联系了,这不需要LLM一个个去数的。从这个角度说,你会发现LLM的训练其实很像培养一个人。
前面这个向量,就叫Embedding,它的长度不一定是字典的长度。我们说过了,神经网络可以任意变维的,你把一个100000个Token的Embedding统一用某个神经网络变维成1000个维度,部分信息损失了,但特定的规律仍在,这个东西就可以用来表示不同的Token。
备注
在机器学习领域,Embedding其实是个更通用的概念,它表示某个概念(“名”)包含的子信息。我们用一只猫的图的所有像素点的信息组成一个向量,这就是一个代表“猫”的Embedding,我们对这个Embedding进行变维,得到一个新的Embedding,它也能代表“猫”,但这个Embedding已经不在原来的维度上了。
Embedding称为某个对象的“特征”,Embedding向量的每个参数称为这个对象的一个“特征参数”,包含更多参数的特征称为这个对象的“高维特征”,变维到更少特征参数的特征,那个特征称为原对象的“低维特征”。
可以看到,同一个对象的高维特征和低维特征的Embedding并不包含相同的信息。它们大部分时候其实是一个key,是查询变维矩阵的关键字。我们看到一只猫,它的样子作为Embedding送入我们的大脑,我们调动的其实是我们过去所有关于猫,动物,哲学,猫吃老鼠等所有的“权重经验”,然后得到某种判断,比如“无害”,“危险”,“可爱”……
由此我想到的是:如果未来出现了一种碾压人类的智能存在,它可能是具有比人类大得多的隐层权重矩阵,它眼中的“猫”,包含的信息比我们多得多,它能发现的相关性也比我们人类多得多,也许能发展出我们完全想象不到的技术方向。
幸运的是,这个世界还是物理的,人类白瞎了那么大的大脑,也不见得就能灭掉没多大大脑的蟑螂。穷尽你的思维,你最终也不过是拿出来一个物理世界的“决策”,大家还是在比物理特性。信息高度给我们带来文明,但并不能让我们为所欲为。
现在的多模态模型,可以同时认识文字和图形,它把图形也切成一块块的,也称为Token,把这些Token也放到训练中,所以,Token其实不但可以表示单个的字词,也可以表示一个简单的图片(大的图片的一部分)。后面我们主要用文字来描述Transformer这个算法,但你需要有这个概念:Token也可以是图。
回到《道德经》的问题上,各位看了这个算法有什么感想呢?我最大的感想是对“名”和“恍惚”有了切身的体会了。我们说的每个意思(Token),其实保存的时候是个向量,这个向量变维后还是向量,多个Token组合在一起,也是向量。这是最直接的“名可名,非常名”,每个Embedding说的都是那个Token,但每个Embedding都是不同的,而且也不是它要表示的那个原始对象。没有Transformer这个具象化的共识,我们很难说清楚名和道的具体语义,因为没有两层语言去描述名和道。现在我们有了。
ROPE
Embedding的下一步,就是Positional Encoding。我们输入一句话让Transformer做后续补全,这句话的每个Token组成一个Embedding的矩阵,输入给模型发现规律。但规律是一个一个Embedding来计算的,和顺序无关,所以最好能让Embedding本身就带着顺序信息,这个信息用什么办法加进去好呢?
Transformer用的算法是ROPE,它是ROtary Position Embedding的缩写,中文可以翻译为“旋转式位置编码”,算法是欧拉公式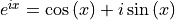 你可以认为它的作用就是在高维空间中把一个向量旋转一个角度。
你可以认为它的作用就是在高维空间中把一个向量旋转一个角度。
如果用两维向量来理解,就是说,你输入一句话:“白日依山”,每个Token被转换成一个两维的Embedding,每个Embedding表示一个二维的坐标,而ROPE就把这个坐标逐个旋转一个角度,成了这个样子:

这里的“白”是第一个位置,不旋转,“日”是第二个位置,旋转一个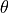 ,“依”是第三个位置,旋转
,“依”是第三个位置,旋转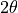 ,如此类推。这样,我们直接拿到Embedding的时候,每个里面都有了一个和位置有关的信息,而且这个信息和前面我们用权重处理Embedding一样,是整体嵌在每个权重上的,而不是一个分离的信息。
,如此类推。这样,我们直接拿到Embedding的时候,每个里面都有了一个和位置有关的信息,而且这个信息和前面我们用权重处理Embedding一样,是整体嵌在每个权重上的,而不是一个分离的信息。
你会发现,现在“白”还是“白”,“日”还是“日”,但隐含着“第一个白”,“第二个日”这个信息在其中了,而且这个旋转还是可以重复的,这和我们说话时的思考也很像:我们确实感知到大致的顺序关系,但只要字数一多,其实我们只是记得一部分,我们不是严格按照某个数字化的顺序去认识这个顺序的。
也许未来我们会发现更多更好的位置编码方法,但我们现在至少可以看出,大模型呈现各种信息的思路不是“数字化”的,而是如何“整体上把信息隐含在另一个维度上”。
ROPE算法本身只有一个不训练的固定旋转参数,所以在那个图上,你会发现它没有占据面积,说明它本身是不带可以训练的参数的。
Attention
ROPE之后,就是Transformer的论文标题强调的核心概念,注意力(Attention)了。这个算法在原论文有一个打开细节后的图示,是这样的:
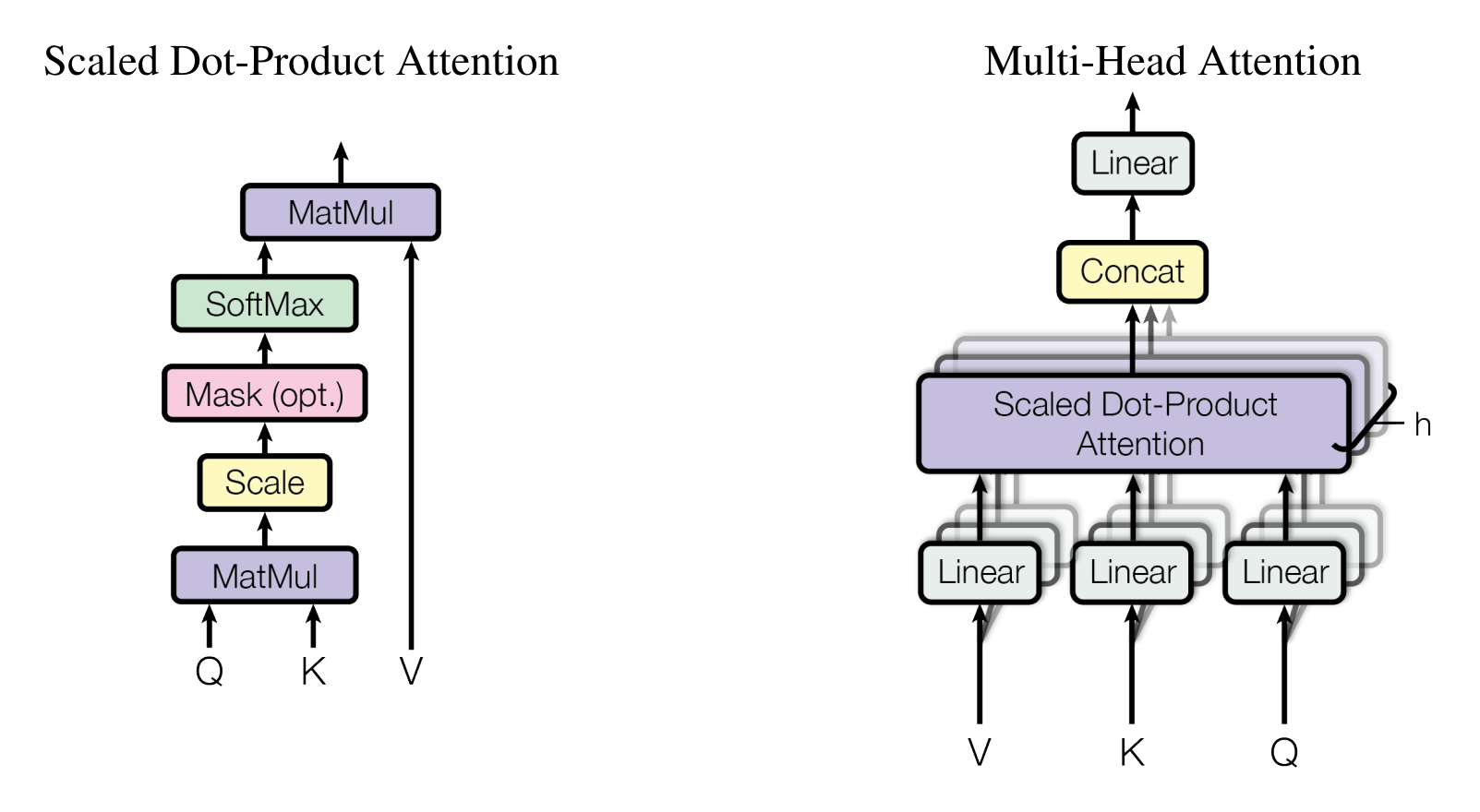
这里的Q,K,V,分别表示Query,Key和Value。听起来是某种查询的行为,实际上不是,这个名字来自Google搜索引擎的图片查询算法,那个算法用一个向量Q去和数据库中的向量K做计算,去查询记录的图片V。Transformer借用了这个算法,但它的Q,K,V全部都是原来的Embedding向量的变维结果。
所以你可以认为,如果你的输入是一个Embedding的矩阵X,那么Q,K,V就都是X的不同变维。如果X表示“白日依(山尽)”,那么,Q,K,V也是“白日依(山尽)”,只是每个变维的权重不同,所以强调的东西有所不同而已。这个计算的核心就是那个SoftMax,SoftMax是一个相关性矩阵(称为ScoreBoard)生成算法,我画个图来展示一下::
Q
|
V 白 日 依 <- K
白 r r r
日 r r r
依 r r r
纵横坐标是输入,r是两个维度对应对象的相关性程度。
这是把不同角度抽象出来的同一句话,计算词和词之间的相关程度。它叫注意力,说的就是我们在说一句话的时候,会关注到前后文之间的关系,从而特别“注意到”说话者想强调什么。整个注意力算法,其实就是在做一件事:把一句话分成三个角度的不同描述,然后用Q,K来强调出这句话的上下文相关程度,最后乘回到这句话上(V),就把这句话重要的部分“高亮”强调出来。
备注
在实际的论文中,encode和decode使用的ScoreBoard是不一样的,decode的ScoreBoard会切掉矩阵中一半对角的内容,这是为了避免“未来词”的影响。在对话的时候,当我们说白的时候,我们是不应该算“日”、“依”和它的关系的,所以必须去掉每行对于未说出来的话对前面的话的影响。这一点对优化KVCache等算法的存在有非常大的影响,在LLM技术中有很重要的作用。但对我们借用这个空间的关系不大。这里专门注释一下,是为了避免对读者建立对LLM的概念造成影响,但其实不影响用于针对道德经主题的理解。
Multi-Head Attention
上面这个算法,可以用不同的权重矩阵,得到多组不同的注意力,然后组合在一起,这就称为“多头注意力”。这里的“多头”,可以理解为“多个思考角度”。
用自然语言来表述这个东西就是说,你告诉我一句话,我从这个角度想一想,从那个角度也想一想,最后组合在一起,这就是我理解这句话的意思了。用一个更具象化的例子来比喻一下:你跟我说“白日依山尽”,我从“唐诗”的角度想想你的意思,再从“登山”的角度想象你的意思,再从“学习精进”的角度想想你的意思,据此来理解这句话你要表达什么,然后综合这些意思,这样我就可以正确理解你的想法,知道你实际想表达什么了。
这种算法,就叫“多头注意力”,它可以被重复多次(注意Transformer架构图中的Nx),这就相当于我们对问题进行了多层的抽象,变维再变维,把逻辑层次抽到很高,最终决定我们怎么思考和讨论这个问题。这就是整个Transformer特征提取的核心。剩下的层,都是标准的神经网络特征提取层,这时特征已经充分暴露了,就是用全连接层来充分提取规律而已。如果不是研究算法本身,我们这里也不需要特别再介绍更多的细节了。
备注
为了让逻辑完整(以便支持后面的MoE的介绍),这里简单解释一下FFN和Add&Norm层的作用。
FFN,Feed-Forward Network是一个标准的全连接层,就是我们前面提到的标准的权重矩阵算法,它的作用就是学习。工程上,一般算法会把d维的Embedding降维成d_h维,分给h个头计算,所以最后的结果就不需要再变维了,因为所有的头合并起来维度会重新变成d,这样重复计算多次层之间的维度都是可以匹配的。
Add&Norm是一种避免多层学习以后结果失真的算法。其中Add称为“残差”,就是把结果和输入加一下,这样结果始终不会离开输入太远。Norm有多种算法,但主要是让结果标准化,让整个结果维持在一个标准的范围上,比如让向量的均值为0,方差为1。这样结果就“标准化”了。所以,这个计算在每步后面都有一个,都是在保证无论迭代多少次,结果都不会走样,算是某种稳压电路吧。
Mixture of Expert
标准的Transformer算法的多头注意力计算方法称为“密集注意力”,这种方法遇到任何问题,都是要走过Nx层的计算,每层都要重复相同的学习网络的。这种方法的缺点是计算成本高,而且也不拟人,因为人在思考的时候其实不会遍历性地把所有角度都思考一遍。所以很多Transformer的变体(比如DeepSeek),都会使用另一个改进,称为MoE,Mixtureof Experts。这算是一种“稀疏注意力”。原理从名字上也可以猜到了,它不会使用所有的FFN网络,而是根据上下文不同,选择不同的FFN记忆(称为“Expert”,专家)。
下面这个图是DeepSeek的论文中对它的MoE的实现的模型图:
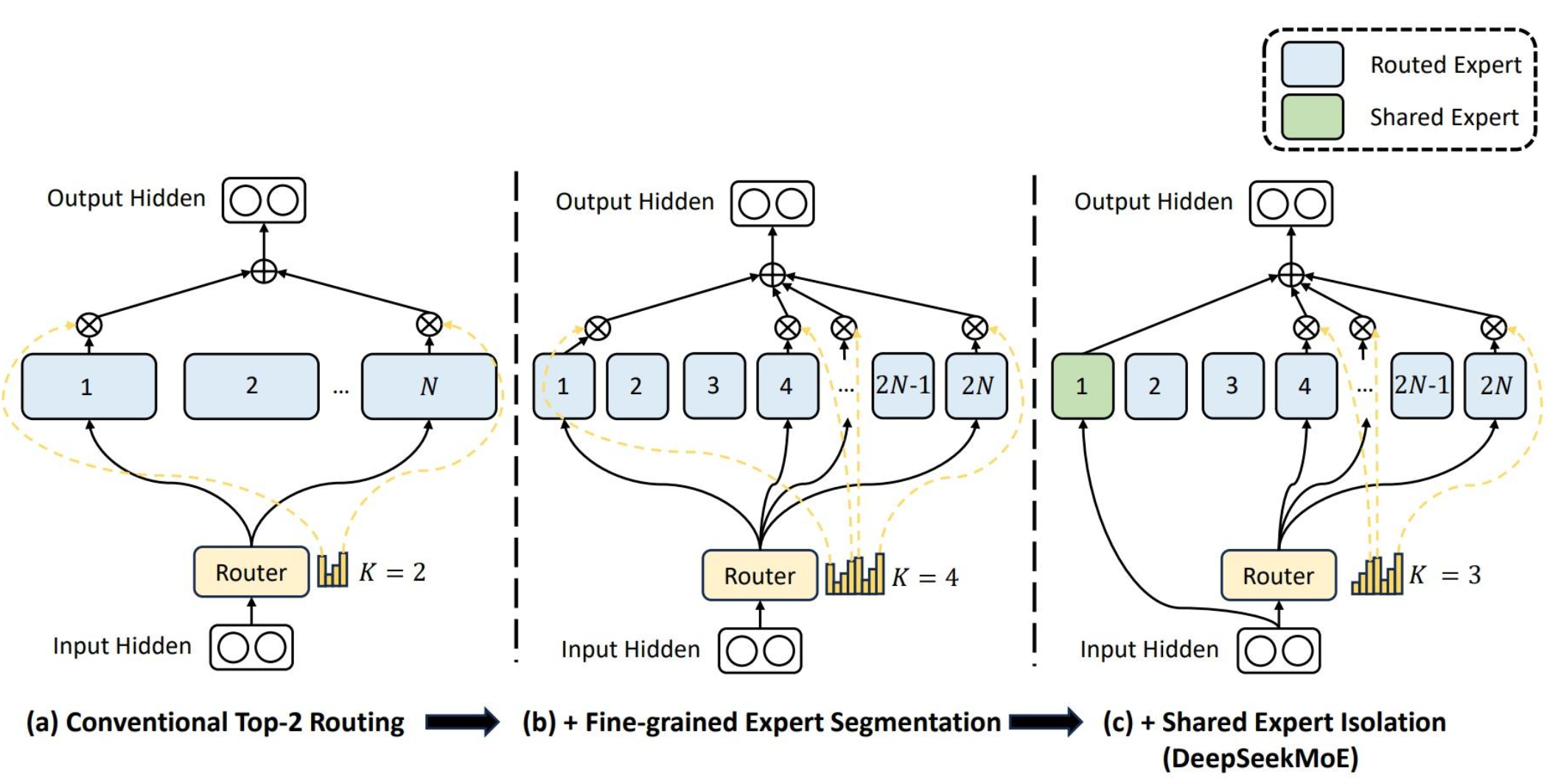
它的修改在FFN层上,在前面多头计算合并以后,输出FFN的时候,并不会只有一个FFN,而是有一组,多头Add&Norm的后的结果在进入FFN层前,通过Router算法选择K个FFN专家支持这一轮计算。
DeepSeekMoE算法把专家分成共享和路由两种,共享专家是每次必选的,路由专家通过一个选择矩阵变维为一个专家数量的logits,得到所有专家的得分,然后选择K个最高分的专家就行了。
MoE更接近人的思维,因为我们听人家说一句话,确实很少把各个知识面都考虑一遍,然后组合出我们的思路,而是直接先大致决定这是哪个领域的话题,然后用那些领域的思考来考虑这个问题的逻辑。这种少数的专业领域,就称为一个“专家(Expert)”,MoE机制,就是用少数的“专家”取代所有的专家,让我们的思考迅速聚焦到特定的领域上。
到这里为止,我们已经解释完Transformer左边的网络了,右边基本上是左边的复制,基本上不需要这里介绍。有些模型干脆就没有左边,其实全部按右边理解就可以了。这个论文不少篇幅在介绍QKV这个算法如何通过保留KV的中间计算结果(称为KV-Cache)来提升计算效率,但这已经是工程问题了,和我们这里讨论的问题无关,我们也不深入讨论下去了。
KVCache和残差流
让我们重新理解一下整个网络。
上面我们一步步介绍Transformer的计算过程,但我们不一定注意到,这里隐藏了一条明确的信息流动的暗流:在每个Nx的层上,每个步骤都是在把一个计算加上原始的值,从而得到输出。其中那个多头注意力的计算,其实是把前面的文字互相之间的关系做了一个ScoreBoard,形成了一个对过往的认知,然后用这个认知“偏置”最后一个输入,而FeedForward这层,我们前面介绍过了,它就是训练的时候记住的训练经验。所以,这两个步骤,其实就是把最后一个Token,先用前文做了一次偏置,然后用过去的经验又做了一次偏置,最后得到输出。
由于这个注意力算法的一些特征,《Attention Is All You Need》的作者发明了一种算法,叫KVCache,每个Attention算法不是需要计算QKV三个向量吗?他们发现如果把之前算好的KV留下来,那么每次增加了Token后,下一个Token就不需要重头计算所有的QKV了,只要用保存好的KV的值直接对着最后一个Token的Embedding做计算就可以了。这样,我们可以这样看待这个计算过程:

所以,其实每步的计算,就是用前文(多头注意力)调整一下方向,然后用知识(前馈网络)又调整一下方向,最后就得到下一个词要说什么。
简单说,在一次算法迭代中,如果我们输入了:
白日依山尽,黄
其中,之前输入的“白日依山尽,”,都被多头注意力的KVCache记住了,然后我们遇到一个黄,就用前文和记忆不断修正它,修正到最后,你就得到了“河”字。这个从黄字,转换成“河”字的整个修正序列(每步计算出来的残差),就是这个计算过程的“残差流”。
可以想象,如果没有KVCache和前馈网络的权重,那么残差就一直是0,这样,无论你跟LLM说什么,它都是重复最后一个字:
白日依山尽,黄黄黄黄……
残差流在实用中常常可以用来破解大模型的思想禁锢(比如不肯回答特定的问题),但对于我们理解大模型来说,它是个特别容易用来理解那个复杂的计算网络概念上到底干了些什么的概念。
思维链
最后我们来讨论几个提示词层面的问题。
思维链技术的应用,极大地提升了LLM的“拟人程度”。它的用法在使用界面上就能看到,我们一开始在ollama上问glm-5.1道德经是什么例子就已经展现过了,LLM不会立即回答你的问题,而是先生成一组前置的Token作为思考,然后才用这个思考的结果也放到输入中,控制后续的发展方向。
所以这个技术和Transformer模型本身关系不大,它主要是把人面对训练是如何思考的,也放到训练数据中,这样每次听到一句话,训练的结果会优先输出思考的部分,然后再基于这个思考的部分输出回答。
传统的LLM方法所有的“思考”,都在隐层中,它里面是什么,其实没什么逻辑,都是一个恍惚中的直接反应,是没有逻辑的Pass Over In Silence。但如果先让这些没有逻辑的隐层数据,先输出一部分Token,然后靠这些Token作为输入来稳固输出,LLM的应答就会更有逻辑。
这种方法我自己有深刻的体会。作为程序员,我写代码前是必然要写设计文档的,设计文档就是把我考虑的各种要素整理成一个个文字表述的“视图”,用这个视图的逻辑去稳固我后续的设计,这个本质是加大逻辑空间的信息量,让逻辑性大于“感性的直觉”(隐层中的无法解释的规律运算),从而让我们的推理的数字化程度更高,而我们知道,数字化对比模拟化的因果,它具有更好的信息传递上的可靠性,这是做复杂的事情的必须的要素,因为这样我们的逻辑可以持续传递下去,而不会因为传递过程中的损失而让最终结果完全偏离我们的初衷。
建简单的平房,可以没有图纸;写简单的程序,可以不写文档;街头斗殴,可以不用安排计划。但如果把这些换成盖高楼,写大型应用,发动战争等,不进行文字化,不基于文字化的一个个“视图”进行逻辑推理,是不可想象的。从这个角度看,文字对人类文明的进步的作用,是非常明显的。人脑可能有某些特殊的手段,可以在大脑中保留一些Token这种明显的信息的,但做复杂的事情,我们还是会通过大量的文字工作,让我们的大脑可以同时使用理性的Token和感性的隐层共同作用,得到更容易重复的逻辑推论。
最近很多AI Agent在不断搞Skill,搞笔记,Memory,本质就是这一点的体现。
上下文
我们前面说了,Transformer这个架构,输出是不断叠加到输入上来进行重新计算的,所以这个计算过程越往后就越慢。这一点,我让你看一个实际的针对LLM的服务(WebAPI)的请求是什么样的你就知道了::
{'max_tokens': 1024, 'temperature': 1, 'stream': True,
'messages': [{'role': 'user', 'content': '为什么1+1等于2?'},
{'role': 'assistant', 'content': '1 + 1 等于 2 是一种基本的
数学概念,它源自人类对数量的理解和符号表示。在现代数学中,
整数1加上整数1被认为是构成基本的组合,即“两”,因此被称作2。
这种规则在我们的数学系统中得到了定义和接受,使得我们能够进
行有效的计算和理解数量关系。\n\n这个概念也反映在其他数学分
支,比如代数、几何等领域,其中1和1的组合确实被定义为2。这种
定义的一致性是数学逻辑和系统的基础之一。当然,这个概念并非不
可改变,例如在某些文化或特定的数学体系中,对于1+1等于何者的
理解可能会有所不同。但在标准的数学逻辑框架内,我们接受1 + 1
等于 2。'},
{'role': 'user', 'content': '如果我假设1+1等于3,可以推演出一
套新的数学体系吗?'},
{'role': 'assistant', 'content': '是的,理论上你可以建立起一个
基于这个假设(即1+1=3)的新数学体系。然而,这样的数学体系会与
我们现有的标准数学概念和逻辑产生冲突。在此体系中,为了保持一致
性,你需要重新定义其他基本数学概念,并建立一个全新的运算规则集。
\n\n例如,你可能需要定义一个新的“加法”操作符,它在两个1之间表现
出不同于我们目前认知中的“加法”(即2)的结果。这将涉及到创建新的
规则和定理来描述这一新的数学系统。\n\n然而,如果你想要与现有数
学体系相兼容或者能够在某种程度上与它交互(比如保留部分原有概念),
那么你可能需要引入更多新的原则和定义来使得这两个世界之间存在一种
接口。\n\n这类问题在数学哲学中经常被探讨,尤其是在探索不同文化或
非标准逻辑系统(如立方数根号系统)时。在逻辑规则固定的情况下,你
可以设计出任何一套数学规则集,但这样的体系在实用性、简洁性和广泛
接受度上可能面临许多挑战。'},
{'role': 'user', 'content': '尝试定义一下这样的体系?'}],
headers={'Content-Type': 'application/json'}
可以看到,虽然这一波我就跟它说了一句话:“尝试定义一下这样的体系?”,但我给LLM发请求的时候其实是把我们说过的话全部发给服务器的,这些所有的话,就叫这次对话的Context(上下文)。现在大部分LLM都没有能力把你说的话更新到它的权重中,所以,它其实就是针对过往的知识(权重数据),和你的上下文,共同决定如何和你对话。但这个对话的时间越长,它的计算成本就越高,反应就会越慢。而且由于一些计算技术的影响(比如KVCache),它需要的内存也越多。
所以,大部分LLM都是有Context大小的限制的,超过一定的长度,LLM就记不住之前说过的内容了。但这一点其实和人很像,人的思考也是有一个上下文的限度的。对写程序的人来说,一个函数超过一定的长度,它的逻辑我们基本上也没法直接通过大脑去校验了。我们只能进行分层,用一个名字代表一段细节,然后思考的时候就聚焦到这个名字上,不再深入它的细节了。
就好比我们大部分人都熟悉的标准程序Hello World::
def main():
print("hello world")
你这里的逻辑就只有“打印‘hello world’”,但实际上要求打印这件事就是很复杂的,比如你首先可能要对字符串进行转码,要选择输出的通道,要和其他共同使用通道的线程进行互斥访问。但我们思考这段逻辑的时候,我们就放弃它的细节了,这样我们才能聚焦在这段逻辑上。这样在这个上下文里面,我们就容易做逻辑思考了。
如果我们把所有逻辑都放在一个Context里面去考虑,我们什么都思考不了。所以,“逻辑”总在某个“上下文”(Context)中呈现,这也是架构设计中“视图”这个概念的本意。
LoRA
上下文可以在不改变模型的情况下用Token改变输出,LoRA是一种不改变模型的权重的情况下,用更多的隐层改变输出的方法。LoRA这个词是Low Rank Adaptation的缩写。LowRank是线性代数中的低秩空间的意思,简单理解,就是把一个高维Embedding先降维,再升维,从而达到“压扁部分信息”的目的。LLM把这样一个层加到原来的前馈网络后面,然后用新的知识去训练,把训练结果只修改这个压扁的知识层,让它强化部分内容,但不改变知识的根本结构。相当于在特定的情形下,补充了额外的知识。
比如你的基本模型知道怎么画飞机,但它不知道航天飞机是什么,你可以不修改原来的模型,而是增加一段隐层,在里面专门在原来的结果上补充“航天飞机”是什么的信息。之后你再要让模型画“航天飞机”,它就能画出来了。
关于这一点的具象认识,请允许我用另一个神经网络来帮助各位读者来理解,这有助于让大家把对LLM的理解扩展到更多的人工智能技术上。
下面这个图是一个文生图(通过文字让AI绘图)软件ComfyUI的计算过程描述:
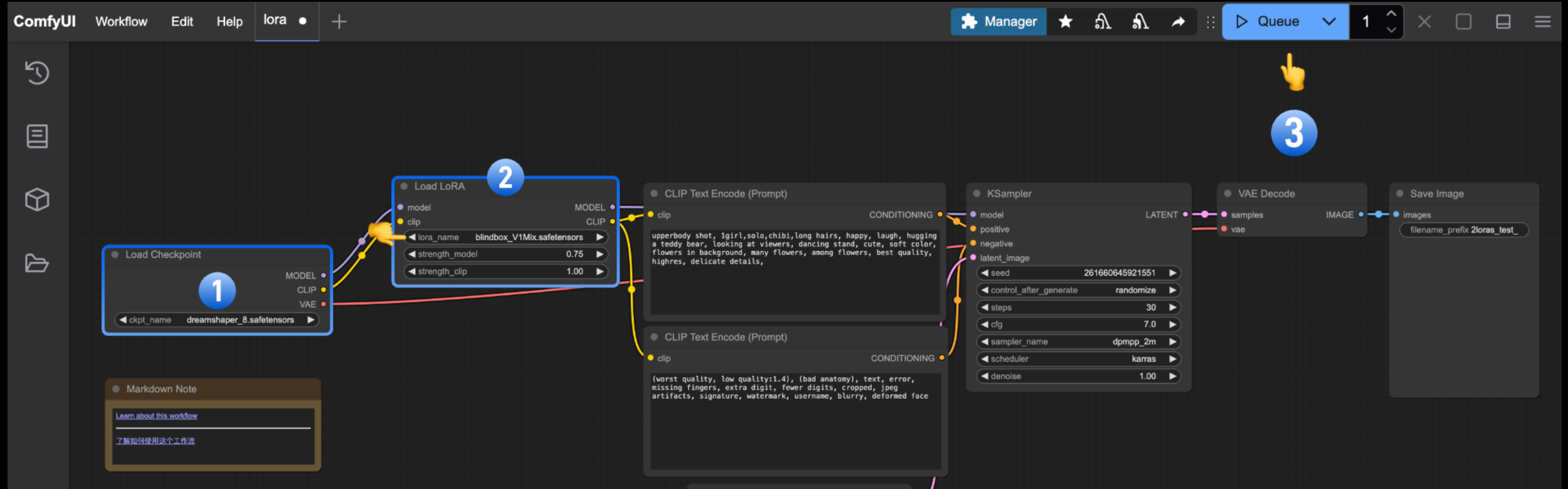
第一步就是它的模型,这一步输出这个模型的全部模型数据(Model)和一些理性的Token(CLIP)(VAE用于对图进行内部格式变换,提升计算效率,和我们的讨论无关,我们先忽略),这个Model和Clip输入到第二步的LoRA上,会得到一个更新版本的Model和Clip,然后再提交给提示词(用户输入的Token),然后进入真正的AI计算(这里的KSampler)。可以看到,LoRA就是对Model和CLIP进行转换的部分神经网络。
我特别用文生图大模型来举这个例子,是因为这可以突出“航天飞机”这样的概念,不是简单几个文字就可以解释的,它包含很多的图片来描述“航天飞机”的形象,你才会感知到什么是“航天飞机”。这种东西就不是简单的Context可以解释的。这里的区别就是信息量的不同。
LLM的LoRA,通常也是这种不能简单解释的东西,比如你用很多的Python程序去训练LLM的Python编程能力,这么多的细节,就不是用Context可以教会AI的。对于没有Python知识的大模型,你可以通过LoRA来补充它这方面的知识。
LoRA和Context这两个概念的存在,很具象化地告诉我们,结构化的数据是怎么在变大以后“曰远,曰逝,曰反”的。我们常常误会我们可以“理性化”地谈任何东西,LoRA就是在告诉你,其实我们只是在一个个独立的Context上理性,我们还有更多的LoRA保存的信息,是完全靠感性去判断的。
信息熵
上面我们把LLM的基本原理介绍完了,在我们进行总结前,让我再科普一些信息论的基本概念,这样我的总结会容易写一些。
我读中学的时候,数字化技术刚刚兴起,当时很多商家都在标榜自己使用了“数字化”技术,比如“数码音响”被认为是“高保真”的。我当时百思不得其解,“数字化”不是更不精确了吗?为什么“数字化”会和“保真”联系在一起呢?
比如你有一段声音:

左边的声音曲线是个模拟量,右边把它数字化了,很明显它变得更粗糙了,怎么就“保真”呢?明明是丢失信息了啊。
如果大家玩过一个叫《我的世界》(Minecraft)的游戏,应该会更有感觉,数字化后的世界只是变得更粗糙了。
这个疑问在我在计算机这个领域工作一段时间后才渐渐消除了:这里这个“高保真”是呈现在信息的传递上的。模拟量也许(作为它自己),是更精确的。但这种精确没法在不同的介质上传递的时候保持:你怎么让麦克风的振动和你声带的振动是“完全一致”的?你又怎么能让放大电路的电压和电流的模拟量和你麦克风的振动总是一样的?
这些都不能进行精确模拟,所以模拟量它也许在源头上是精确的,但根本不能传递。能传递的是数字。当声音被描述为一组数字,那么这组数字无论保存在磁带上,电路上,光纤上,甚至在口头上说出来,它都是那个数字,一点都不会改变。所以它“保真”。
这种“保真”的东西,我们称它为“信息”,它不被任何介质所限制,具有超越介质的自有特征。
我们感知到的所有“精确”,都来自“信息”的一致性。也就是说,某个信息,用这种方法表达计算结果是某个样子的,换一种方法表达,它还是那个样子的,这两个表达我们就认为它们是同一个表达。
比如我们保存一段声音,分别这样表达::
base=10, wave=10, 9, 14, 10, 23, 7,
base=16, wave=a, 9, e, a, 17, 7
我们用了不同的数字,但内在的信息是一样的(上面那个用了十进制,下面那个用了16进制)。虽然这种一直都会有一些双方认可的基本信息前提(比如上面这个至少我们承认了两种表达都表示了声音,都承认了阿拉伯数字等等),但在某些基本的前提下,信息是可以被在不同的介质上复制的。
这样我们就会引入“信息熵”这个概念了。它是一种计算信息密度的方法,读者很容易可以查到它的公式,但公式所表达的信息不是我们这个上下文要讨论的内容,我就不放这个信息了。我用下面这个例子来给读者比喻一下:
我告诉你一个信息::
444444445555555566666666
这要24个数字才能表达,我们姑且不严格地定义它的信息量是24。然后我们在纸上这样记录它::
84 85 86
忽略算法本身的信息量,后面这个表达只需要6个数字就可以表达上面的字符串,因为它就是表示8个4,8个5,8个6。后面这个表达,包含的信息量和前面是完全是一样的。所以,我们认为6才是上面这个字符串的真正的信息量。
我们还可以进一步优化,如果所有情况下,第一个数字都是8,那么前面这个数字还可以表达为::
8:4 5 6
这个信息量是4。如此类推,如果我们穷尽一切办法(这是一种“理想”的情况),压到最后,就是这个4了,那么无论你怎么表达这个信息,都不影响它的信息量就是4。这个4,就是所有这些信息的“信息熵”。
所以,信息在不同的介质上,用不同的方法保存,可以有不同的信息量,但这个量有一个最小限制,这个限制就是这些信息的信息熵。信息论有理论可以评估一组数字的理论信息熵,但工程上我们有更简单的办法理解它:把你的所有数字化的内容保存为一个文件,然后反复去压缩它,压到最后不能减少了(甚至可能会增大),这个大小大致就是这个信息的“信息熵”的大小了。
信息熵是信息的“最小限度”,这个最小限度的存在,决定了你没法用更少的“差异”(信息存储都来自某种特定的差异,比如内存就是靠高低电压的不同来决定0和1这两个信息的)来存储更多的信息。一个神经网络就那么多个权重,你不可能在其中保存比这个更大的信息熵。
大脑思维模型的各种问题,都来自这个信息熵的约束。你的大脑本质上是这个客观世界的粗糙的“数字孪生”。这好像用乐高积木搭的房子模型,细腻的房子被用粗糙的颗粒表达。它一定程度上“像”客观世界,但它只是你提取的部分信息。这个信息同时由Token和模型组成,它们共同决定你的决策。
大脑的天性就是不断想办法压缩信息。这不但是减少存储需求的需要,更是减少每个独立的上下文的信息量需要。你会明显地感受到它总是用类似“一生二,二生三,三生万物”的方式去线性化得到的信息。简单说,就是给你几个具象,然后说“如此类推”。在维特根斯坦等人的理论中,其实就是用数学归纳法。比如自然数有无数个,不可能一个一个存下来,但可以这样压缩它:
最小的自然数是1(我知道不同教材有不同说法,我这里就用这个吧)
如果当前的自然数是n,那么它的下一个就是n+1
就算我用字的个数来表示它的信息熵,这也不超过100个字。所以,你看,无论如何我们都是用类比降低我们的信息量的。现实中很多人就是看了三个例子(前两个构成规律,第三个用来验证),就开始总结“所有的请求都是这样的”,比如“三人成虎”就是一个典型的例子。
三人成虎只是大脑压缩的需要,从来不能保证这是现实,它只是用尽力而为的方式去模拟我们的观察而已。这也说明了,我们是不可能纯靠逻辑推理就能正确认识规律的。
最典型的情况就是对波粒二象性的理解:很多人都接受不了一个东西居然同时是波和粒子。因为他们用来理解微观粒子的类比基础就是宏观世界的球体。但谁说微观就是球体的“如此类推”呢?你只是通过很多宏观观察认为它在宏观观察上呈现了波和粒子的一部分特征而已,这和它的本体是什么没有直接关联的。
所以,我们其实永远都不知道这个世界的“本源”,我们一直在和我们的观察在较劲。比如有些学派认为“数学”是世界的本源,而不可能改变的,其实这同样有可能是因为我们的观察本身被训练成了这样的规律而已。你根本分辨不了这是外部的规律,还是我们观察本身的规律。这个道理就好像你通过数码相机去认识的这个世界,你永远不会知道“像素点”是一种客观存在,还是你的观察能力的限制。
小结
这样,我们就把LLM的基础技术科普完了。在这么多的训练数据中,我们希望给读者的大脑训练出这些概念的LoRA:
- 道和名
道是外部刺激,或者说道描述引起外部刺激的那个对象,但因为它先于Token,我们也没法用Token去描述它。名是Token。
- 天地(世界)和Token
天地是我们的隐层,当我们把其中一部分概念说出来的时候,这些概念就成为Token。“说出来”这件事本身也在改变隐层(因为它会反过来形成输入)。所以,我们的思考,已经在改变我们的“天地”。我们想清楚苹果落地的逻辑,和我们认为天圆地方的时候,我们的“天地”是不一样的。这和是否唯心无关,因为我们并没有说天地能改变外来的刺激。
- Context和LoRA
我们同时使用Context和LoRA思考,我们用外部的文字(比如写设计文档,写策划文案)来增强我们大脑有限的Context(思维链)上下文长度。我们做越复杂的事情,我们就需要越多的外在文档,因为LoRA不能传递,只有数字化的Context才能传递信息,构成人和人之间的配合,以及在不同的上下文中让我们选中更正确的MoE。
- MoE
我们在每次思考的时候,只是调用少数几个专家来进行思考,我们任何思考都不是“全面”的。文档化增强了我们每次思考挑选MoE的能力。人类的进步离不开文字和文档体系的发展。
用这种概念空间去看待我们的思维,我们就可以更清楚地看清楚我们的思维误区。
大脑可以保存的信息量是有限制的,而且它会用分散传播的形式去修改权重。如果多余的信息来了,你没法说它具体稀释了哪部分的权重数据,但无论如何,它最终就是要丢掉部分信息的。这样一想,你就会发现,信息还真不是越多越好的,怎么抓住主要矛盾才是我们进行思维的关键。这个情形在未来AI技术发展越来越强的时候,应该会表现得越来越明显。
备注
这么想的话,真的有必要少刷手机,因为无效的信息真的会吞没你的隐层的。
就现在来说,我觉得我们现在还是比人工智能聪明,因为我们感知的数据还是比人工智能多的(比如LLM就只感知文字,文生图就只感知图或者视频),但这种情况未来肯定是会改变的。但是否因此人工智能就全面取代人呢?我认为还有很远的路要走,至少它的能耗模型就没法和人比,它独立生存的能力都堪忧。不过这些就不在我们的讨论范围内了。
对大脑行为的一些综合想象
这一个小段让我用一个没有“小心求证”的“大胆假设”来综合一下我们的信息。
我感觉,我们大脑,由于基因的不同,每个人生成了类似而不同的神经网络结构,里面的权重是一些噪声数据。小的时候,我们被最基本的感知所训练,慢慢形成了最初的思维结构,那个阶段的记忆,被后来快速增长的权重数据(大脑本身的发育)所淡化,变成淡淡的温馨回忆。所以很多研究都说人不会记得很小年龄时的东西。“小时候”,只是一种感觉。
之后,我们进入发育期,基础模型慢慢被更多的熵所填满,所以这个阶段我们记忆力特别好,因为这个阶段,我们的神经网络的信息熵还很低,可以填入更多的数据。等我们成年了,基础模型已经训练完成了,我们只有少数几个LoRA区留下来用来记一些短时间训练的东西,所以我们就很难学新的知识了,只能用这些LoRA和我们原先写的笔记来研究一些新问题,但我们再也无法恢复到过去那种快速记住很多新知识的阶段了。
然后随着我们的老去,我们先失去了更多的LoRA区,记忆越来越差,慢慢凸显的就是过去的老记忆,这些记忆随着没有了LoRA的干扰,反而变得更加清晰,更容易生成和过去相关的Token。
最后,随着我们一层层丢失我们的基础模型,我们变回了当初那个任性的小孩,在秋风中随风飘散,零落成泥。
重新认识逻辑
有了上面的基本概念,我们也许可以重新认识一下逻辑的原理。
我们脑子对逻辑的最基本认识,是相关性,比如这样::
好吃的东西 --> 吃
能吃饱的东西 --> 饿了就吃
烫手的东西 --> 避开
这种最直接的判断,是应激反应,是记在我们的隐层参数中的。深入分析这些判断的特征,你会发现,我们做各种判断,首先是有个目的:好不好吃,只有你有吃的需要,你才会提取它,没有这个需要,你就会忽略它。所以,言有君,事有宗。每个思考和决策,都是带着目标的,没有这个目标,你不知道你要提取什么特征。
第二呢,我们每次都关心那个对象的部分特征。比如这里“好吃的东西”,和“烫手的东西”,可以是同一个对象的特征。“同一个对象”本身,也构造了一种相关性。
由于这样的关联的存在,制造了矛盾。比如同一个东西,它可以有“好吃”这个特征,也可以同时有“烫手”这个特征。那到底是吃还是避开呢?这就会有矛盾。矛盾本身,也是一种现实的相关性,也是我们的现实经验告诉我们,“避开的东西”,“吃”不到口中。如果也要用前面的图表达,那就是::
避开的东西 --> 没法吃
把这些相关性连起来,就是逻辑。比如::
苹果 --> 好吃的东西 --> 吃
好吃的东西 --\
>--> 等凉了再吃
烫手的东西 --/
逻辑是靠点(穷举)出来的,当我们有很多条件的时候,这些条件把可能性空间分成了很多的格子,每个格子我们都单独针对我们的结论进行了对比,对比处理的结果的全集,就是整个可能性空间的所有可能性的全集。每个针对结论的可能性全集,就变成了我们分析下一个可能性的特征。
这种东西还是得用一个具体的技术案例来做类比,请读者原谅这方面我只能用我的老本行来讲了。我尽量找简单一点的例子,希望不是做计算机的同学也能看懂。
比如我们做一个计算机最常见的内存分配算法:我们有一片连续的内存,我们要能从里面分配部分数据,用完以后可以还回来。
我们先做最直接的设计:按顺序分配:来一个请求,就分配一段,如果不够,就再分配一段,一直到分配完了就行了。
图示一下:

我们细看一下这个设计,这完全契合我们前面说的逻辑空间的两个特点:
我们的分类都包含了“在沉默中传递”的信息的,我们都知道“之前分过的空间”,“剩余的内存”,“下一个分配空间”是什么意思。
我们没有无穷的东西,我们可以点清所有的可能性。我们用的是递归的方法表达了这个“无穷”。
但这不是我们思考这个问题的完整方法,因为我们还没有“穷举”。我们现在仅仅是有了一个骨架。我们要穷举所有的可能性,那么我们就要问了,如果之前分过的空间被释放了一部分怎么办?
最简单的解决方案:“当作没有”。这样一回答,我们整个空间就自洽了,我们穷举完了。没有其他可能性了。
但一般我们当然不喜欢这样的解决方案,太浪费了。也为了让我们的问题复杂一点,我们用复杂一点的解决方案:剩余空间是一个链表,我们遍历这个链表,直到找到一个大于要求内存空间的连续空间,我们再分配:

你看,我们现在的分类更多了,但我们还是保持可穷举的状态的,我们还是看到了所有的可能性,同时,我们还是知道,我们仅仅是在这个逻辑空间里面自洽,这个逻辑空间之外的属性,都是被我们忽略的。比如我们不考虑内存电路坏了,这个东西就说不通了这种情况。一般上层程序员可能会觉得我这么说有点极端,但对于我们这些做OS的来说,处理RAS异常(一种处理硬件错误的策略或者方法)实在是非常常见的考虑方向。反正无论如何吧,我们所谓的”有逻辑”,从来都是在某个范围内来说的。
这样穷举,我们会得到一个这样的“结论”:即使我们有足够的空间,我们也有可能分配不了我们需要的内存,因为这些内存可能形成“碎片”:加起来空间是够的,但每个都不足以分配需要的空间。
为了解决这个问题,我们再改进我们的分类方法:我们不是找到哪个空间足够我们就分给它,而是找所有的空间,其中最小的一个,才用来分配,这样碎片会“少一些”。
我们现在更复杂了,但正如我们前面说的,我们还是能够穷举所有可能性。我们还可以继续这样分类下去,但前提是我们引入的分类不能无限增加,因为我们的穷举能力是有限的,一旦可能性的数量多到一定的程度,这个空间就必须被作为一个整体去看待,我们就看不见细节了,我们看到的是“大”,“大”就不可“名”了。
所以,逻辑思考是什么呢?我们是尽量把一个我们思维控制得住的概念空间进行穷举,穷举完了以后,我们发现我们通过一些控制,让结论是有限的,然后把它作为另一个空间的“在沉默中传递“的整体来使用。
如果我们控制不住它的结论空间,那么它就成为一个不可名的混沌,它就是不可控的。在其他空间中我们无法进行推理。
比如这个内存分配算法,假定我们用于前面说的Transformer算法,我们在做Transformer计算的时候,要分配KVCache,计算的过程中要分配临时向量,计算完了我们会释放内存。在我们考虑这个算法的时候,我们不再关心我们是一个个“可剩余空间里面找到内存的”,我们用了我们穷举过的所有可能性的结论空间:“我们分配的内存是不会重叠的”,“我们已经经过考虑,尽量减少了碎片的”……这样,我们才能思考一个复杂的问题。
如果我们没有穷举这个内存分配算法的可能性,那么我们也没法用它思考Transformer算法如何做,我们就必须把我们前面说到的自注意力算法,前馈网络算法,和具体的“已使用空间”,“剩余空间”一起考虑,这个组合出来的空间一起考虑,这样需要穷举的可能性就更多了,这个空间就更没有结论了。
这些每个可以这样穷举的独立空间,我称为一个“封闭的概念空间”,在不同的领域中,它有别的名字,比如,在架构设计中,这称为一个“视图”(View),在程序设计中,这称为“函数”,“类”,“结构”,“模块”……这些东西的背后,都是可以被穷举的,结论有限的,“封闭逻辑空间”。
逻辑推理,就是在这种一个个的独立抽象中穷举可能性的行为。而设计,很大程度上是合并推理结论相同的可能性空间,你看我们前面把无限种分配释放的可能性抽象成“剩余空间是一个列表”这一种分类。这样我们穷举的成本就降低了。
我们做各种战略设计,程序设计,工程设计……本质都是这么个原理:我们分不同层次,不同方面,不同角度,对必然会发生的“天网”进行染色,让我们知道,一旦我们选择了某些东西,有些结果就已经注定的,我们只能在剩下的空间里面再做选择。这样,我们后面的穷举的成本就越来越低了。
所以高层战略,架构设计,这些工作都像艺术,因为在初期你进行空间切割的时候,你是有很高的自由度的,可能呈现成不同的样子,但一步步下去,就越来越确定了。我们无法穷举所有的可能性,因为可能性空间是无限大的,人脑的算力摆在那里。这一点,对于现在的LLM来说,也是一样的,LLM也不能越过这个限制,因为,如果计算机能越过这个限制,就意味着一个系统可以预测这个系统的未来,这个系统自己递归自己,这就不是逻辑了,在逻辑上这个系统自己自相矛盾了。
所以,很多人觉得LLM继续发展,就会可以处理更长的上下文,就可以在无限的可能性空间中推理出我们人脑推理不出的结论来。但如果你明白逻辑的原理,你就知道,你给LLM无限大的可能性空间,LLM只会用不封闭的逻辑空间给你形成结论,形成幻觉。
从LLM重新认识道德经
有了上面这个逻辑空间,我们可以用新的Token去解释很多道德经中我们直接用自然语言很难解释的东西。
你可以把我这段补充看作是整本书的一个LoRA模型,有它可以稳固你的Token数据,没有它,也不见得有多大问题。
在正文中,我会在每个翻译的后面用“[机器学习解释]”这样的标题单独讨论这样的引导信息。这种“[机器学习解释]”只在V3版本才有。